An implementation to general HashMap based CRC64(by golang)
never give up!
introduction
As who have studied data structure knows, hashing is best fast way to look up a data. The cost of it is just some spaces. The time compexity is $O(1)$.
Here's how it works:
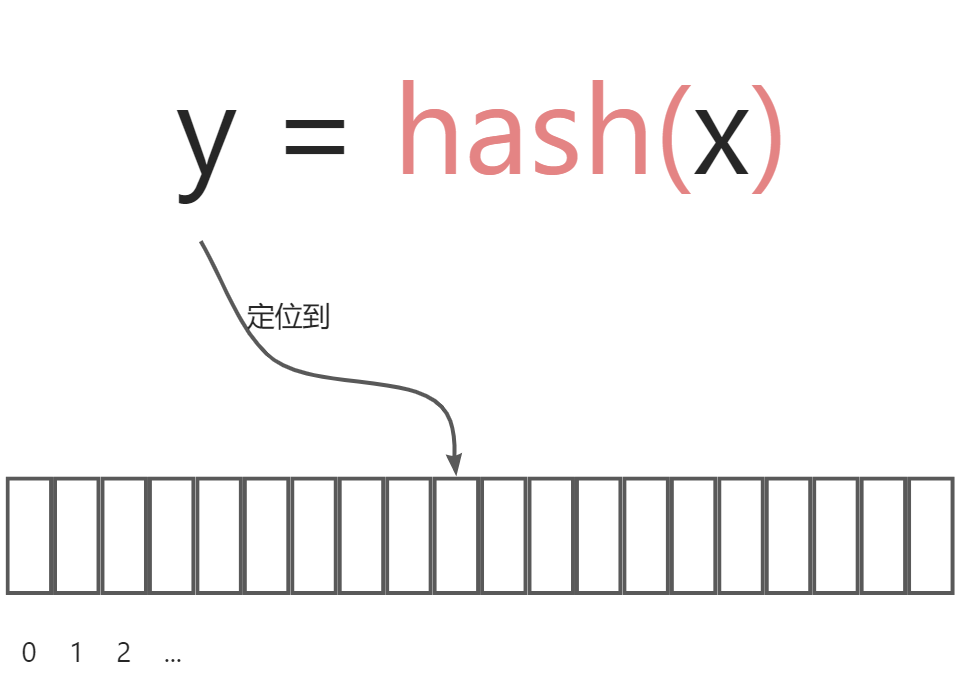
First, we need to define a hash function ,which functions to map data x to some index y on an array. For instance:
$$ y = x\ \%\ 19 $$
There is a problem: many x will map to the same y。Supposing that \(x_1 = 7, x_2 = 19\), they will all be put on index 7 (that is the eighth postion on an array). $$ x_1\ \%\ 19 = 7 \ x_2\ \%\ 19 = 7 $$
This time, collision occurs! There are four ways to solve:
open address method
Linear probe
Quadratic probe
hashing again
linked-address method (using linked-list)
These methods have been introducted in oceans of blogs. We will not repeat again. But they emphasis more on theoies instead of practicing. Example codes in them is just for teaching, and can not been used to production enviroment. From the point of our view, there are many shortcomes:
- supporting only mono data type. Actually, It is impossible for us to implement a hash map for everay data types we use. We need a hash map supporting any datatype.
- utilizing rather naive hash function. For instance:
mod. Actually,the operation mod may be suiable for integer, but may not for the other data type.
For these two problems, our strategy is: first, using generic programming,and then integrating the hash function CRC64(x) mod len(array) into our codes. Because the good distubution traits of CRC64, there will be rare hash collisions under such implemetation.
principles
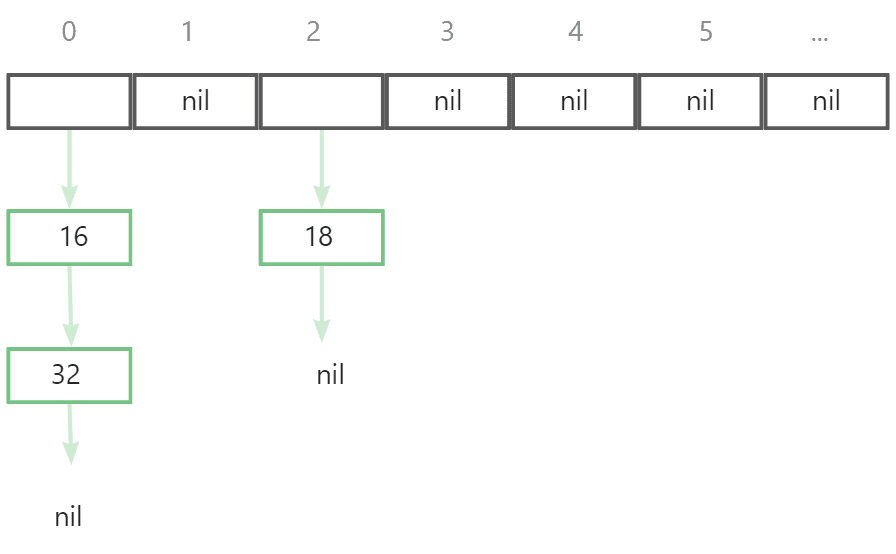
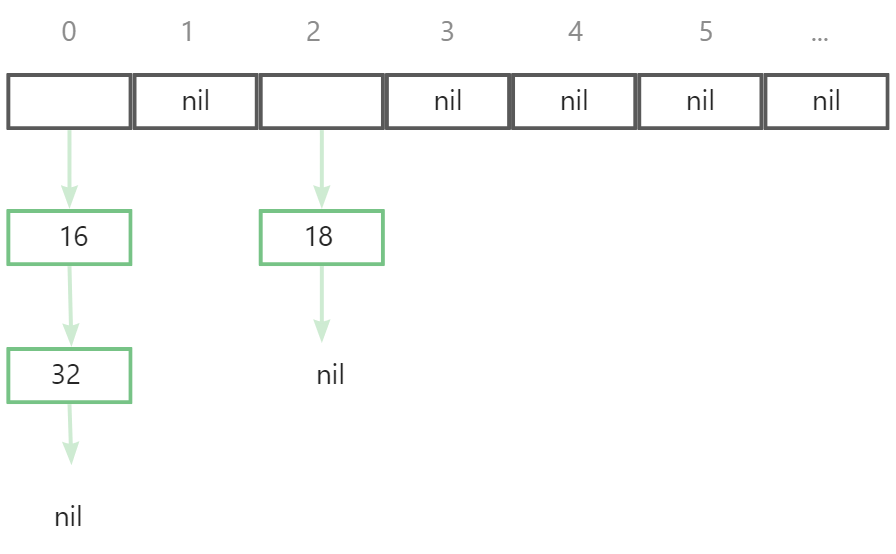
We use chained address method to relief hash collisions. As the following picture: Each element in array is a linked-list. When collisions occur on some index, the newest data will be put in the linked-list of correspond index.
Assume that 16, 18 now are in a hash map where 32 will be put. After the hash value was calculated by hash function (no care about what it is), we get a hash value 0 which means 32 will be put after 16 in the linked list of index 0.
In Java language(version 1.8),the method to solve hash collisions is also like this in HashMap, but heap was used instead pure linked-list. When the length of linked-list grows to 8,the linked-list will be convert to red-black tree(RBT). Apparently, the average look-up time of RBT fast that linked-list RBT . But after our near one-day's pondering, we commit a consense that if a hash function which have been chosen can generate uniform hash value on any data, the length of linked-list will not be so long (about 3). As a result, the performence improvement will not be clear or obvious.
Some hash functions here:
- DJB2 series
- FNV series
- SDBM
- CRC32、CRC64
- Murmur series
Many performence such as collision rate, velocity, distribution across multiple datasets of there them have been tested in :
There are many new best hash function,for examples: SipHash、HighwayHash、xxHash、MetroHash:
CRC64, which appears to have fewer collision rates, is chosen for this paper. The reader may choose according to the actual situation.
implementation
implemeted by golang.
stucture
First, we define the data structure of linked-list。next denote the next node of linked-list node,key represents the indentifior of data,value is data.
type _HashEntry[K comparable, V interface{}] struct {
next *_HashEntry[K, V]
key K
value V
}
Next, we define hash map structure. An array will be maintained, which data type is a pointer to a linked-list.
size denote the count of data.
type HashMap[K comparable, V interface{}] struct {
threshhold int // If the array length exceeds the threshold, the array size is expanded
inflateFactor float64 // percentage, required for inflate array
array []*_HashEntry[K, V] // array
size int // the count of data.
}
And then, define hashmap's constructor.
The initial size of array will be 16. let inflateFactor be 0.75, which means when the size of hashmap accounts for 75% of the length of array, the array will be inflated. threshhold will be calculated by the following equation. We use it to avoid calculating many times on quering, and was actually seen as a flag to decide inflating or not.
$$ \rm{threshhold} = len(array) \times inflateFactor $$
func NewHashMap[K comparable, V interface{}]() *HashMap[K, V] {
initSize := 16
return &HashMap[K, V]{
threshhold: 12,
inflateFactor: 0.75,
array: make([]*_HashEntry[K, V], initSize),
size: 0,
}
}
hash function
We directly convert struct into string, and transform string to bytes. Last, hash bytes to an usinged integer by golang's crc64 package.
func hash(key interface{}) uint64 {
var table = crc64.MakeTable(crc64.ECMA)
bytesBuffer := bytes.NewBuffer([]byte{})
switch key.(type) {
case string:
str := key.(string)
err := binary.Write(bytesBuffer, binary.BigEndian, []byte(str))
if err != nil {
panic("invalid key!")
}
default:
err := binary.Write(bytesBuffer, binary.BigEndian, []byte(fmt.Sprintf("%v", key)))
if err != nil {
panic("invalid key!")
}
}
return crc64.Checksum(bytesBuffer.Bytes(), table)
}
get size
just return size.
func (this *HashMap[K, V]) Size() int {
return this.size
}
set data
First, the hash function is used to calculate the hash value, because it is an unsigned integer, the range is very large, so the array length is modulo to determine the final position 'index'.
After being put into the linked list in the array, the data size is increased by 1. If the data size 'size' is found to be greater than or equal to 'threshhold', then the array is inflated. How to infalte an array is described below.
func (this *HashMap[K, V]) Set(key K, value V) {
index := hash(key) % uint64(len(this.array))
node := &_HashEntry[K, V]{
key: key,
value: value,
}
if this.array[index] == nil {
this.array[index] = node
} else {
for i := this.array[index]; i != nil; i = i.next {
if i.key == key {
i.value = value
break
}
if i.next == nil {
i.next = node
}
}
}
this.size++
if this.size >= this.threshhold {
this.inflate()
}
}
get data
After the index is calculated, the data can be taken out by traversing .
func (this *HashMap[K, V]) Get(key K) (V, bool) {
index := hash(key) % uint64(len(this.array))
if this.array[index] == nil {
return *new(V), false
}
for node := this.array[index]; node != nil; node = node.next {
if node.key == key {
return node.value, true
}
}
return *new(V), false
}
delete data
After the index is calculated, delete the node in linked-list,size minus by 1
func (this *HashMap[K, V]) Delete(key K) {
index := hash(key) % uint64(len(this.array))
if this.array[index] == nil {
return
}
if this.array[index].key == key {
this.array[index] = this.array[index].next
this.size--
return
}
for node := this.array[index]; node.next != nil; node = node.next {
if node.next.key == key {
node.next = node.next.next
this.size--
return
}
}
}
inflate array
When the data size reaches a certain size (determined by inflateFactor and threshhold), the array needs to be scaled up to reduce hash collisions.
This step regenerates an array twice as long, then iterates through the original array, putting all the data back into the new array.
/*
*
infate array,an re-hash all data.
*/
func (this *HashMap[K, V]) inflate() {
if len(this.array) <= (1 << 61) {
newLength := len(this.array) * 2
newThresh := int(float64(newLength) * this.inflateFactor)
oldArray := this.array
this.threshhold = newThresh
this.array = make([]*_HashEntry[K, V], newLength)
this.size = 0
// re hashing
for i := 0; i < len(oldArray); i++ {
for node := oldArray[i]; node != nil; node = node.next {
this.Set(node.key, node.value)
}
}
}
}
tests
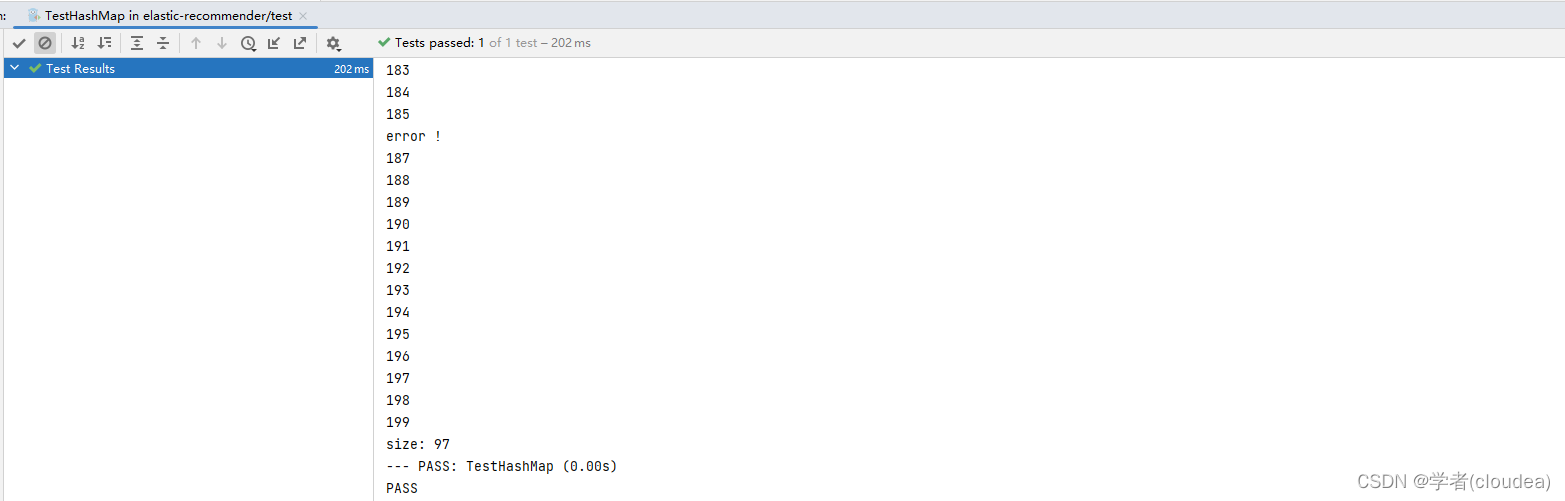
The following codes verfifed the correctness the above implementation.
func TestHashMap(t *testing.T) {
m := structure.NewHashMap[int, string]()
for i := 0; i < 100; i++ {
m.Set((i), fmt.Sprint(i+100))
fmt.Println("insert: ", i)
}
m.Delete(38)
m.Delete(54)
m.Delete(86)
m.Delete(101)
m.Delete(-1)
for i := 0; i < 100; i++ {
v, ok := m.Get((i))
if ok {
fmt.Println(v)
} else {
fmt.Println("error !")
}
}
fmt.Println("size:", m.Size())
}
The result shows here: